
Advanced Planning for Autonomous Vehicles Using Reinforcement Learning and Deep Inverse Reinforcement Learning
Autonomous vehicles promise to improve traffic safety while, at the same time, increase fuel efficiency and reduce congestion. This project concentrates on the path planning problem of autonomous vehicles in traffic, as shown in Figure 1. Each vehicle has a couple of actions to take, such as maintaining its current speed, switching to the left/right lane, speeding up and braking. We model the interaction between the autonomous vehicle and the environment as a stochastic Markov decision process (MDP).
Figure 1: The traffic on multi-lane road.
The state of the MDP is defined using the positions of the autonomous vehicle, and the number and positions of the environmental vehicles around the automnous vehicle. The road geometry is taken into consideration in the MDP model in order to incorporate more diverse driving styles.
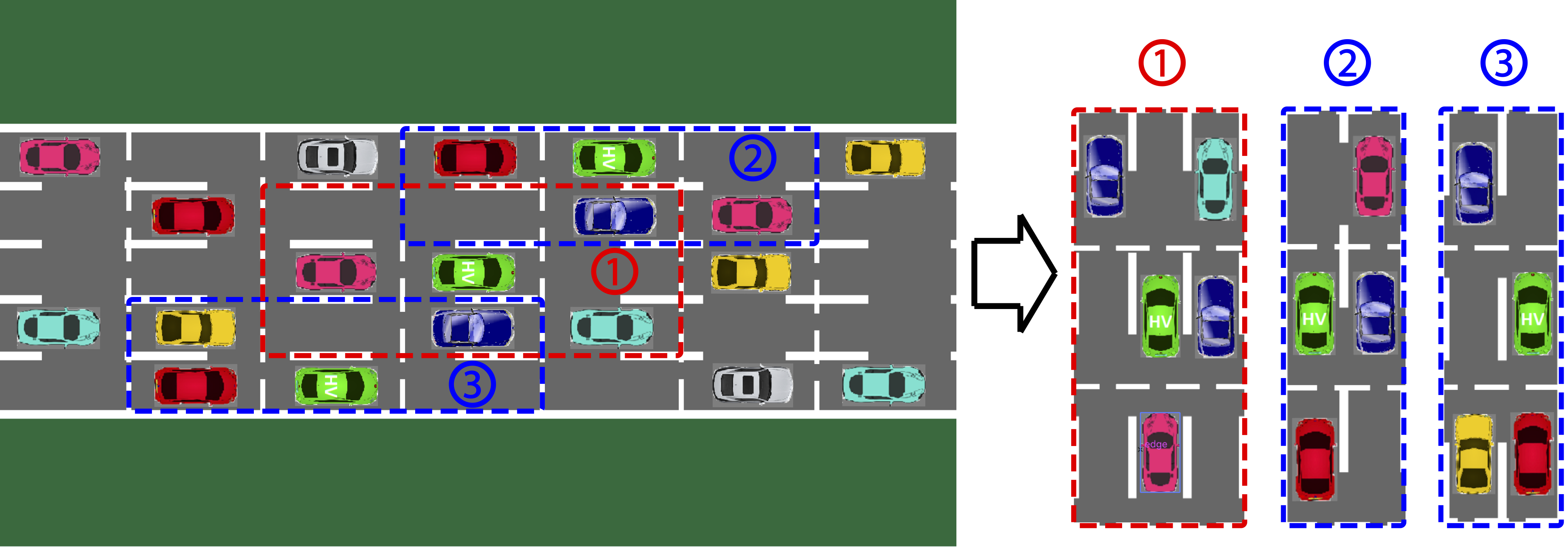
Figure 2: The cells and the definition of the state: (1) 9-cell internal-lane state, (2) 6-cell left-boundary state and (3) 6-cell right-boundary state
The core problem of an MDP is to find a policy $\pi$ for the agent, where the policy $\pi:S\rightarrow A$ specifies the action to take at the current state $s_t$. The goal is to find the optimal policy $\pi^*$ that maximizes the cumulative discounted reward over an infinite horizon: \begin{align} \label{eqn:OCP} \ \pi^* = \arg \max\limits_{\pi} ~ \mathbb{E}\Big[\sum_{t=0}^{\infty} \gamma^t R(s_t,\pi(s_t))\Big], \end{align} The desired, expert-like driving behavior of the autonomous vehicle can be obtained using two approaches.
First, we design the reward function of the corresponding MDP and determine the optimal driving strategy for the autonomous vehicle using reinforcement learning techniques.
Second, we collect a number of demonstrations from an expert driver and learn the optimal driving strategy based on data using inverse reinforcement learning. The unknown reward function of the expert driver is approximated using a deep neural-network (DNN).
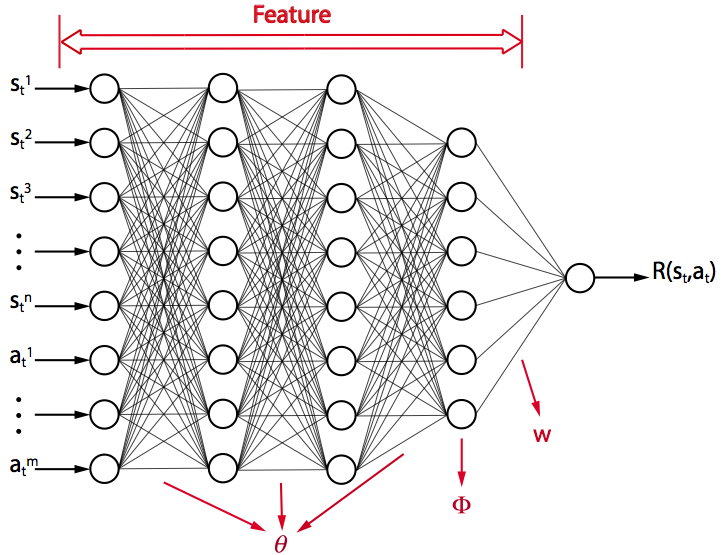
Figure 3: Deep neural-network feature function and reward.
Movies for demonstrating the typical driving styles such as overtaking and tailgating are available here and here.
Selected Publications
- You, C., Lu, J., and Tsiotras, P., "Driver
Parameter Estimation Using Joint E-/UKF and Dual E-/UKF Under Nonlinear
State Inequality Constraints,'' IEEE Conference on Systems, Man
and Cybernetics, Budapest, Hungary, Oct. 9-12, 2016.

- Okamoto, K., and Tsiotras, P., "A New
Hybrid Sensorimotor Driver Model with Model Predictive Control,''
IEEE Conference on Systems, Man and Cybernetics, Budapest, Hungary, Oct. 9-12, 2016, (best student paper finalist). -
You, C., and Tsiotras, P., "Vehicle
Modeling and Parameter Estimation Using Adaptive Limited Memory
Joint-State UKF,'' American Control Conference, Seattle,
WA, May 24-26, 2017, pp. 322-327, doi:
10.23919/ACC.2017.7962973
- You, C., and Tsiotras, P., "Real-Time Trail-Braking Maneuver Generation for Off-Road Vehicle Racing," American Control Conference, Milwaukee, WI, June 27--29, 2018, pp. 4751– 4756, doi: 10.23919/ACC.2018.8431620
- You, C., and Tsiotras, P., "Off-Road High-Speed Cornering for Autonomous Rally Racing," IEEE Transactions on Control Systems Technology, Vol. 26, No. 2, pp. 485-501, 2021, doi: 10.1109/TCST.2019.2950354
- You, C., Lu, J., Filev, D., and Tsiotras, P., "Autonomous Planning and Control for Intelligent Vehicles in Traffic," IEEE Transactions on Intelligent Transportation Systems, Vol. 21, No. 6, pp. 2339-2349, June 2020, doi: 10.1109/TITS.2019.2918071
-
Okamoto, K., and Tsiotras, P., “Data-Driven
Human Driver Lateral Control Models for Developing Haptic-Shared Control
Advanced Driver Assist Systems,” Robotics and Autonomous Systems,
(accepted January 2019). doi:
10.1016/j.robot.2019.01.020
-
You, C., Lu, J., Filev, D., and Tsiotras, P., “Advanced Planning for Autonomous Vehicles Using Reinforcement Learning and Deep Inverse Reinforcement Learning,” Robotics and Autonomous Systems,
Vol. 114, pp. 1-18, April~2019, doi:10.1016/j.robot.2019.01.003
.
Sponsors
This work is sponsored by Ford Motor Company and NSF.